
Triggering and Monitoring a dbt Cloud Job with Azure Data Factory
Ready to master your data pipelines?
Dive into our latest blog to discover how Azure Data Factory can trigger and monitor dbt Cloud jobs. Learn how to execute dbt transformations right after loading data into the bronze layer, creating a seamless, end-to-end pipeline in Data Factory. Don't miss out on this technical deep dive!
Overview of the Pipeline
An overview of the pipeline can be seen in the picture below:

The pipeline consists of four main activities:
Fetching the dbt Token (get_dbt_token)
Triggering the dbt Job (run_dbt_job)
Capturing the dbt Job Run ID (get_dbt_run_id)
Monitoring the dbt Job’s Status (until_cloud_job_finished)
This pipeline uses two parameters:
dbt_job_id
dbt_account_id
These parameters can be found in the dbt Cloud platform under Deploy > Jobs.
After selecting the job that needs to be scheduled, clicking the ‘API trigger’ button will display these parameters:


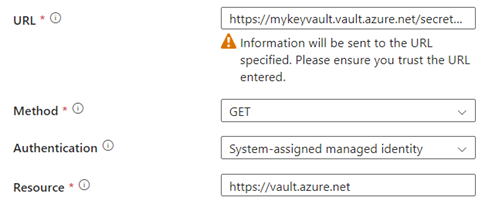
1. Fetching the dbt Token
A Key Vault is used to store the dbt token. The connection is made using managed identity authentication. Be sure to store the key in the Key Vault and copy the name of the vault and the token. The dbt token can be created in the dbt account settings.
The URL should look like this:
https://mykeyvault.vault.azure.net/secrets/mytokenname?api-version=7.0
Where ‘mykeyvault’ is the name of the Key Vault and ‘mytokenname’ is the name of the dbt token.
The full activity should look like this:
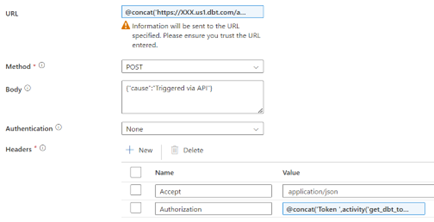
2. Triggering the dbt Job
The ‘run_dbt_job’ activity is responsible for triggering the dbt job through a web activity. This activity sends a post request to the dbt API to start a job. The request includes an Authorization header, containing a token retrieved from the ‘get_dbt_token’ activity.
The URL should look like this, where ‘account_id’ and ‘job_id’ are used from the parameters:

Note: XXX should be filled in with the right dbt URL.
The body of the request should include:

For the Authorization header, use the token retrieved from the Key Vault:

The full activity should look like this:
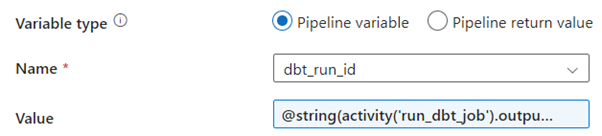
3. Capturing the dbt Run ID
Once the dbt job has been triggered, the next step is to store the job run ID in a variable. The ‘get_dbt_run_id’ activity captures the job run ID from the output of the ‘run_dbt_job’ activity. This initializes a variable named ‘dbt_run_id’.
The value should look like this:

The full activity should look like this:
4. Monitoring the Job’s Status
The final step is the ‘until_cloud_job_finished’ activity, which continuously checks the status of the dbt job until it is either completed or fails. The activity uses an ‘Until’ activity. The condition is based on the value of the ‘dbt_job_status’ variable. This variable indicates whether the job is still in progress (True) or has finished (False).
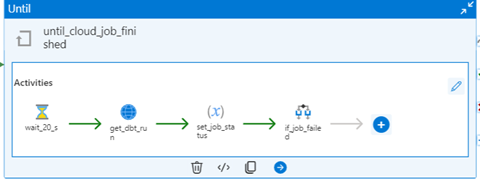
Within the loop, several actions are performed:
Wait Activity: A ‘Wait activity’ pauses the pipeline for 20 seconds before rechecking the job status. This helps avoid excessive API calls.
Job Status Check: A ‘WebActivity’ queries the dbt Cloud API to check if the job has been completed. The job status (‘in progress’ or ‘error’) is returned and stored in the ‘dbt_job_status’ variable.
The URL for this request is:

Be sure to also add Authentication header:

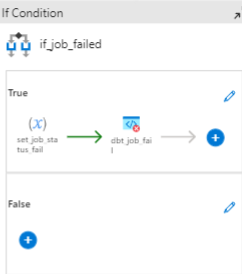
Job Failure Handling:
If the dbt job fails (i.e., if ‘get_dbt_run’ returns an error), an if condition activity checks the error flag and triggers a Fail activity to halt the pipeline execution, logging an error message. This step is needed to be able to trigger a pipeline failure.
1) The if expression looks like this:


2) Inside, there are two actions:
set_job_status_fail:
This action sets the ‘dbt_job_status’ to False. This ensures that the ‘Until’ loop is stopped.This contains the following expression:

dbt_job_fail:
This will trigger the pipeline failure if the dbt job run returns a failure.
1) This is stored within an ‘if loop’ with the following expression:

2) The set job fail sets the variable ‘dbt_job status’ to “False” if a fail is recorded.
Wrap up
By leveraging the connection between dbt Cloud and Azure Data Factory, you can seamlessly trigger dbt transformation jobs right after loading data into the bronze layer. This integration ensures the integrity of your data processes by preventing dbt jobs from running if any previous steps fail. With this setup, you can maintain a smooth and reliable end-to-end data pipeline, enhancing your data management capabilities. Whether you're dealing with complex data workflows or aiming for more streamlined operations, this integration provides the tools you need to keep everything running effectively.
Want to implement this in your workflow, too?
Benoît is a data professional passionate about AI and analytics.