
DataBricks Data & AI Summit ’24: What’s to come?

You might have missed this year’s ‘DataBricks Data & Summit’ that held place from 10th of June until the 13th of June 2024 in San Francisco. If you did, this blog post will get you up-to-speed on the development of what is to come in the world of DataBricks. While recordings of the summit are made available online, we will share what we are most excited for!
A quick recap on DataBricks
DataBricks is a fantastic tool that includes all necessary components for a Data Platform; from provisioning an all-purpose data lake, to supporting Data Engineers, enabling business users in self-service reporting to aiding data scientists in their search for gold in data.
We often use following components to explain the functionalities of DataBricks:
·Delta Lake: A unified data storage, management and sharing layer that is often referred to as ‘the data/delta lake’. You can store whatever you want, whenever you want at whatever pace you want.
Unity Catalog puts a governance layer on top of the delta lake, making sure that the lake doesn’t result into a swamp. Make your data easily accessible or make sure it is only accessed by those who are permitted to. The Unity Catalog allows for a very granular security on schema and table level.
Delta Live Tables, Workflows, Notebooks, Spark Jobs, …: This is the bread and butter of your data engineering. Connect, extract, transform and load your data from one location to the other and convert from data to insights.
DataBricks SQL: The SQL component provides the functionalities of a Data Warehouse to our Data Lake (often referred to as a Data Lakehouse). You can connect a lot lot of tools to this SQL-based component and work with your data.
Mosaic AI: A set of AI-based components aiding all who use DataBricks in providing state-of-the-art functionalities and making AI available to the masses. This includes AutoML, MLFlow, Vector Searches, Feature Stores and much more.

DataBricks the latest and greatest: what’s new?
DataBricks is now 100% Serverless
DataBricks becomes 100% serverless! Before this release, pipelines and developers needed to wait minutes before the spark clusters were made available. With DataBricks now becoming 100% serverless, gone are those minutes wasted waiting for your cluster to start-up; gone are those minutes trying to find the cluster configuration that best suits your workload. Going serverless means reduced ETL-times and a better development experience and efficiency.
DataBricks LakeFlow
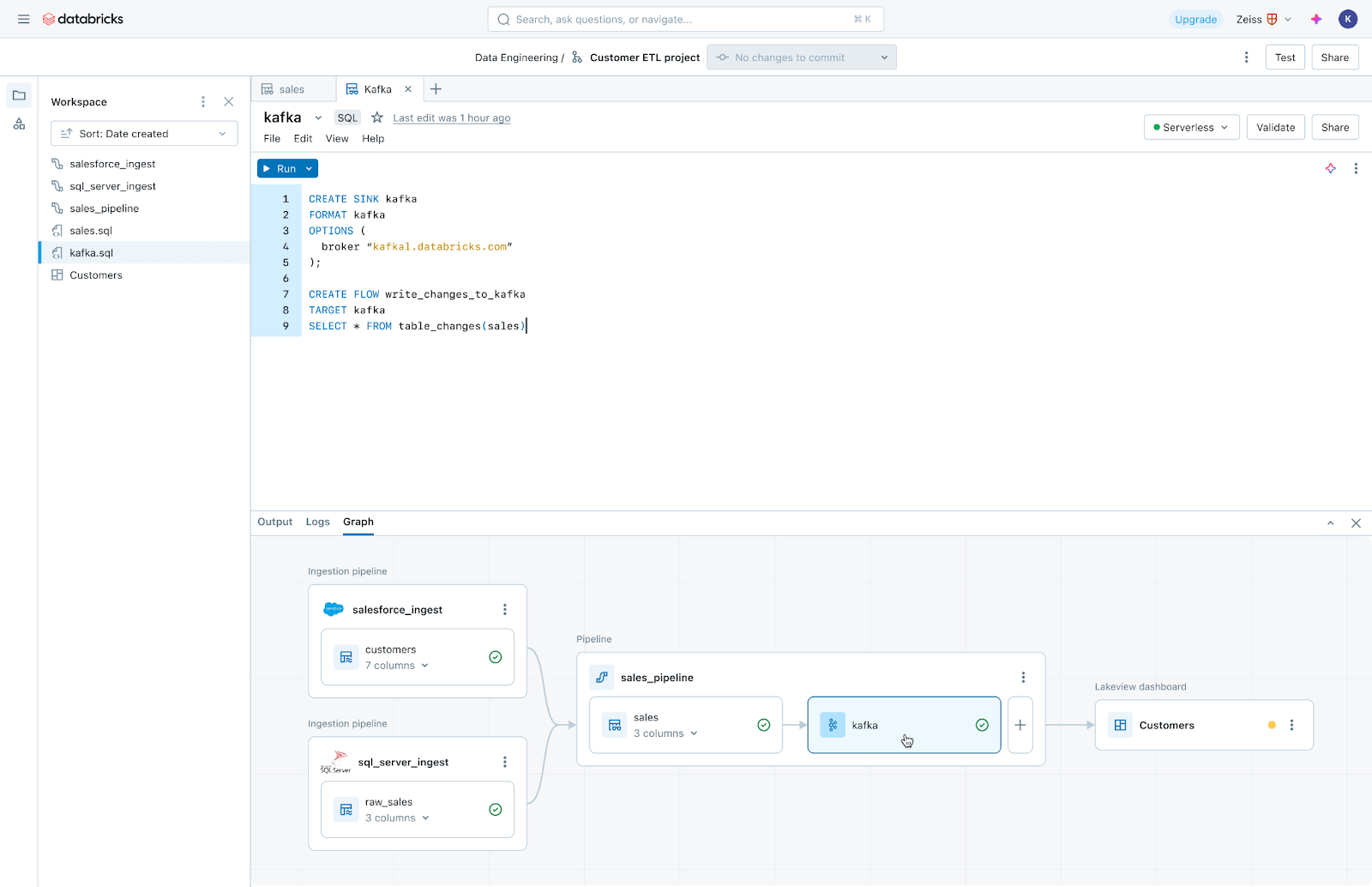
To get data to the Data/Delta Lake, we often relied on external tools (such as Azure Data Factory/Synapse Pipelines). The (planned) release of ‘DataBricks LakeFlow’ allows you to ingest data with DataBricks-native components. LakeFlow easily connects to on-premise and cloud sources, allowing you to create complex ingestion pipelines. The image below depicts an ETL which connects data from an on-premise SQL Database and joins it together with a cloud-only SalesForce application; transforming it using Kafka.
Expanding Mosaic AI Features
DataBricks AI Toolbox ‘Mosaic AI’ has gained lots of new features, with a core focus on Large Language Models and RAG’s.
Mosaic AI Model Training: This service makes it easier to train AI models, whether you’re improving an existing model or starting from scratch.
Shutterstock ImageAI: Shutterstock has launched a new AI that creates custom images for businesses, trained on their extensive image collection.
Mosaic AI Vector Search: This Vector Search tool is now widely available and better than ever and contains new features for data control and improved search quality.
Mosaic AI Agent Framework: DataBricks is introducing a new framework that simplifies building AI systems using your own data, ensuring safe and managed data use.
Mosaic AI Model Serving: Now, not only can you serve models in real-time, but you can also serve agents and use our Foundation Model APIs for various workloads.
Mosaic AI Tool Catalog: DataBricks has created a catalog where customers can find and share tools for AI applications, including SQL and Python functions, model endpoints, and more. Plus, our Model Serving now supports direct function calls, allowing for even more flexibility.
We urgently need to update our Mosaic AI toolbox!

Delta Lake 4.0
If the above was not enough, we are happy to share that delta 4.0 is coming! This format will be available on Apache Spark 4.0 computes and up. With the delta 4.0 format you will receive multiple reliability and performance updates. Moreover, you have several utility features to look forward to, such as type widening and (automated) identity columns.
In delta lake 4.0 Databricks takes the open source data format even one step further by introducing the UniForm dataformat. In UniForm the metadata of the classical Hudi, Iceberg and Delta Lake are combined. By adding this wide support, This means that you will get a "one data format to rule them all". By doing this we believe that Databricks is on a good first step to end vendor lock-in by data siloes.

Unity catalog is now open source
Unity Catalog is now Open Source: Unity Catalog enables a unified security and governance data catalog for your whole enterprise. By open sourcing Unity Catalog, enterprises with a multi-cloud and hybrid environment will benefit from deploying Unity Catalog as an enterprise-wide data catalog.
Wrap up
In this blog, we’ve reviewed the DataBricks basics and zoomed in on the hottest announcements of DataBricks Data & AI Summit ‘24.
Do you have any questions or need help implementing a data solution?
At Plainsight we are always in for a chat! ☕
👉 Reach out via LinkedIn or our contact form
Anxious to know what Plainsight could mean for you?
Read more “About us”
Consider “your career at Plainsight 🚀”