
What’s in your Fabric: Data Warehouse or Data Engineering?
The possibilities with Microsoft Fabric are endless. This often raises questions. Which component should I choose?
This article focuses on the choice between Data Warehouse or Data Engineering.
Before we slice the cake, let’s start with some context

we get a lot of interesting questions on Microsoft Fabric. One of the recurring topics is which ETL engine to choose? Can we use multiple? And when to use which?
To dissect the question. It all comes back to people, processes, technology and data.
The cake
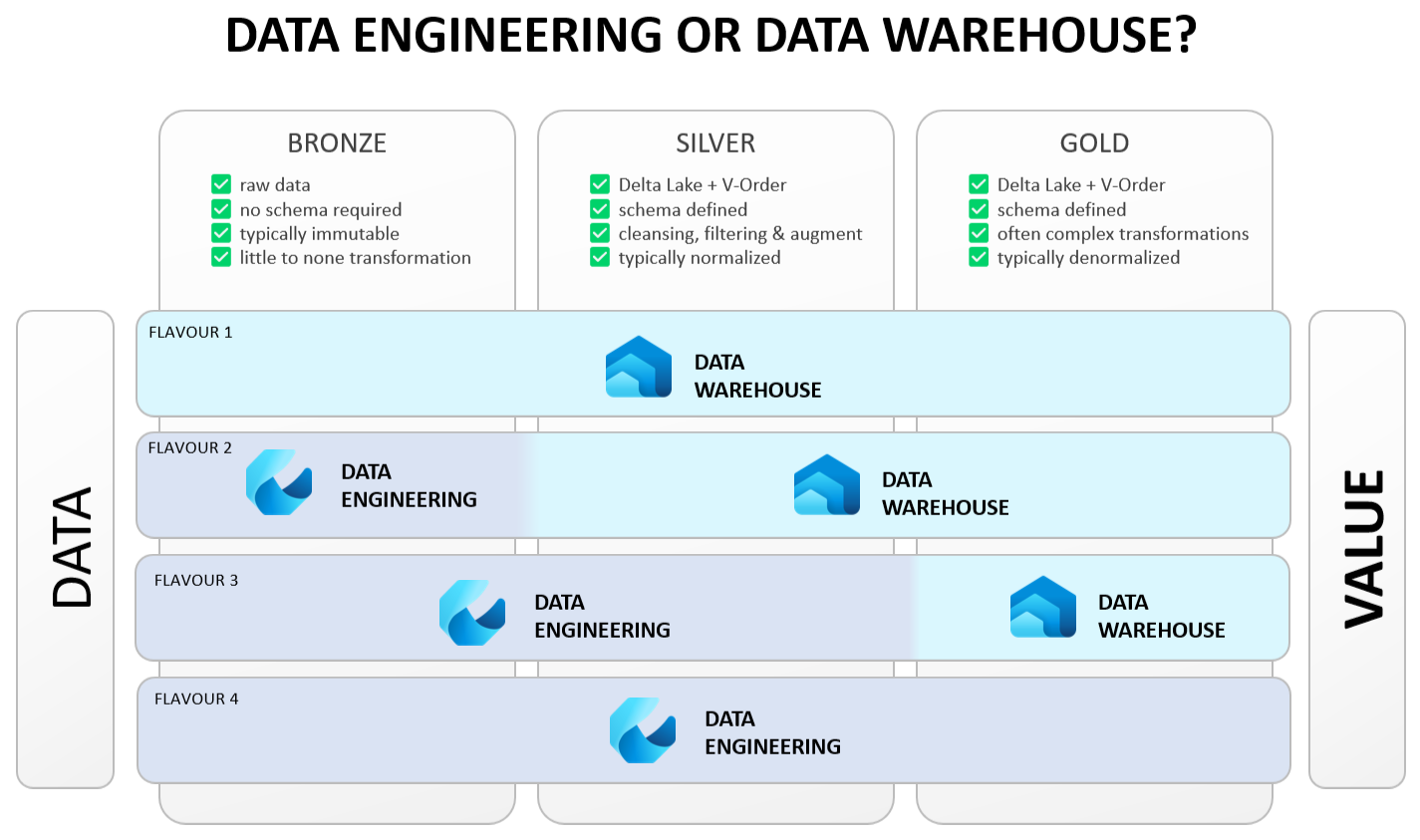
Fabric houses multiple engines. You can use data lakehouses, data warehouses, notebooks (PySpark, Spark, Spark SQL, SparkR), …
Next to the different engines, you will also have decisions concerning the layers in your data architecture. For simplification, we use the medaillon architecture (Bronze, Silver, Gold). However, don’t blindly follow this because it just sounds good. There are simpler and more advanced data architectures that could be a better fit for your organization. A good architect combined with a pragmatic approach often wins.
As depicted in the picture you can use a combination of Data Warehousing and Data Engineering or choose a single engine.
Flavour 1: Data warehouse all the way!
Flavour 2: I want my data raw! But hey, I also like the Data Warehouse.
Flavour 3: I love the flexibility of notebooks, but I am a SQL “Server”!
Flavour 4: Data engineering all the way!
Which factors influence your decision?
Data
What are our data sources today and tomorrow? Structured, semi-structure, unstructured, streaming
What are our data products today and tomorrow? Dashboards & reports, Machine learning models, …
…
People
What are the skills of our developers? Python, SQL, Scala, …
What is the mindset towards certain technologies in the development team? “SQL is oldskool 😎”, “SQL is still the language that is most widely adopted”
What skills are there in the market today and tomorrow that you would need?
…
Process
Which process do we have in place to go from data to value?
…
Technology
Do we already have existing analytics engines that need to be migrated towards Fabric?
Which technology is the most future-proof?
Which technology creates the least vendor lock-in?
Which technology supports our process from data to value the best?
…
Budget
Every technology comes at a cost. Our workload could be more cost-efficient in one engine or the other.
As can be noticed, lots of factors influence this decision and it could even be more criteria for your organization.
It also doesn’t need to be the one or the other. Some examples:
In the future our organization will have more and more semi and unstructured data. If your team is mostly SQL-oriented and there isn’t a large appetite to switch to programming languages such as Python, it could be a good option to land all our data in the raw zone using Data Engineering. Structure the data and from there start with Data Warehousing.

If you mostly have relational data and the team is strong in SQL. Why make it harder than it is? Opt for a complete setup using the Data Warehouse platform.

If you have a wide variety of data sources and a talented team of big data engineers, the technological data products that we need to deliver vary widely from tables to reports to machine learning to … we would suggest a full Data Engineering solution.

The Conclusion
Microsoft Fabric gives you the luxury of different engines that can be used to support your data use cases.
People, processes, data, technology & budget influence your architectural decisions. Choose wisely.
A good architect and healthy pragmatism always wins.
Any additional questions or guidance?